
Stepfun introduces Step-Audio-AQAA: Fully End-to-End Audio Language Model for Natural Voice Interaction

Rethinking audio-based human computer interactions
Machines that can respond to human speech with the same expression and natural audio have become the main target in intelligent interactive systems. Audio modeling expands this vision by combining speech recognition, natural language understanding, and audio generation. The models in this space do not rely on text transformation, but use speech alone to understand and reply. This is critical not only for accessibility and inclusion, but also for smoother human-machine interactions in applications such as voice assistants, audio-based storytelling and hands-free computing.
Limitations of cascading voice pipelines
Despite advances in audio comprehension, there is a clear challenge: Most systems still rely on separate module chains for speech-to-text, text processing, and text conversion conversion. This modular approach can reduce performance and responsiveness due to accumulated errors and latency. Furthermore, these pipelines lack expression control, making them unsuitable for subtle tasks such as emotional conversations or dynamic voice synthesis. The ideal solution would be a completely unified model that understands audio problems and directly produces expressive audio answers, thus eliminating all text-based mediation.
From token-based models to fully unified LALM
Several methods have tried to solve this problem. Early approaches such as HuggingGpt and Audiogpt took advantage of cascading architectures that combined separate pronunciation and language models. These systems struggle in real-time voice interactions as they expand their task coverage. Later works, such as Vall-E, Speechgpt, Audiopalm, and Qwen2-Audio, introduced token-based systems that convert audio into discrete representations. However, even if these models are primarily output text and require separate sound encoders, limiting their ability to produce expressive direct audio responses.
Introduction to step-audio-aqaa: end-to-end AQAA system
Researchers at Stepfun have launched Step-Audio-Aqaa, a completely end-to-end large audio model designed specifically for audio queries-Audio answers tasks. Unlike previous models, Step-Audio-AQAA directly converts spoken input into expressive spoken output without converting it into intermediate text. The architecture combines a dual code book, a 130 billion parameter backbone LLM called Step-Omni and a natural speech integrated flow vocoder. The integration of these components allows seamless low-latency interactions.
Tokenization, architecture and voice control
The method begins with two independent audio tokens, one for language features and the other for semantic pronunciation. Language tokens are based on spanning forms, using a code book of 1,024 tokens to extract structured speech elements, such as 16.7 Hz phonemes. Meanwhile, the semantic tokenizer (inspired by Cosyvoice 1.0) encodes acoustic richness of 25 Hz with 4,096 tokens. These are interwoven at a ratio of 2:3 and pass them to Step-Omni, a multi-mode decoder LLM trained on text, audio and image data. After that, the model outputs a three-code sequence of audio and text tokens, which Vocoder converts to fluid speech. This setting allows for fine voice control, including emotional tone and voice speed.
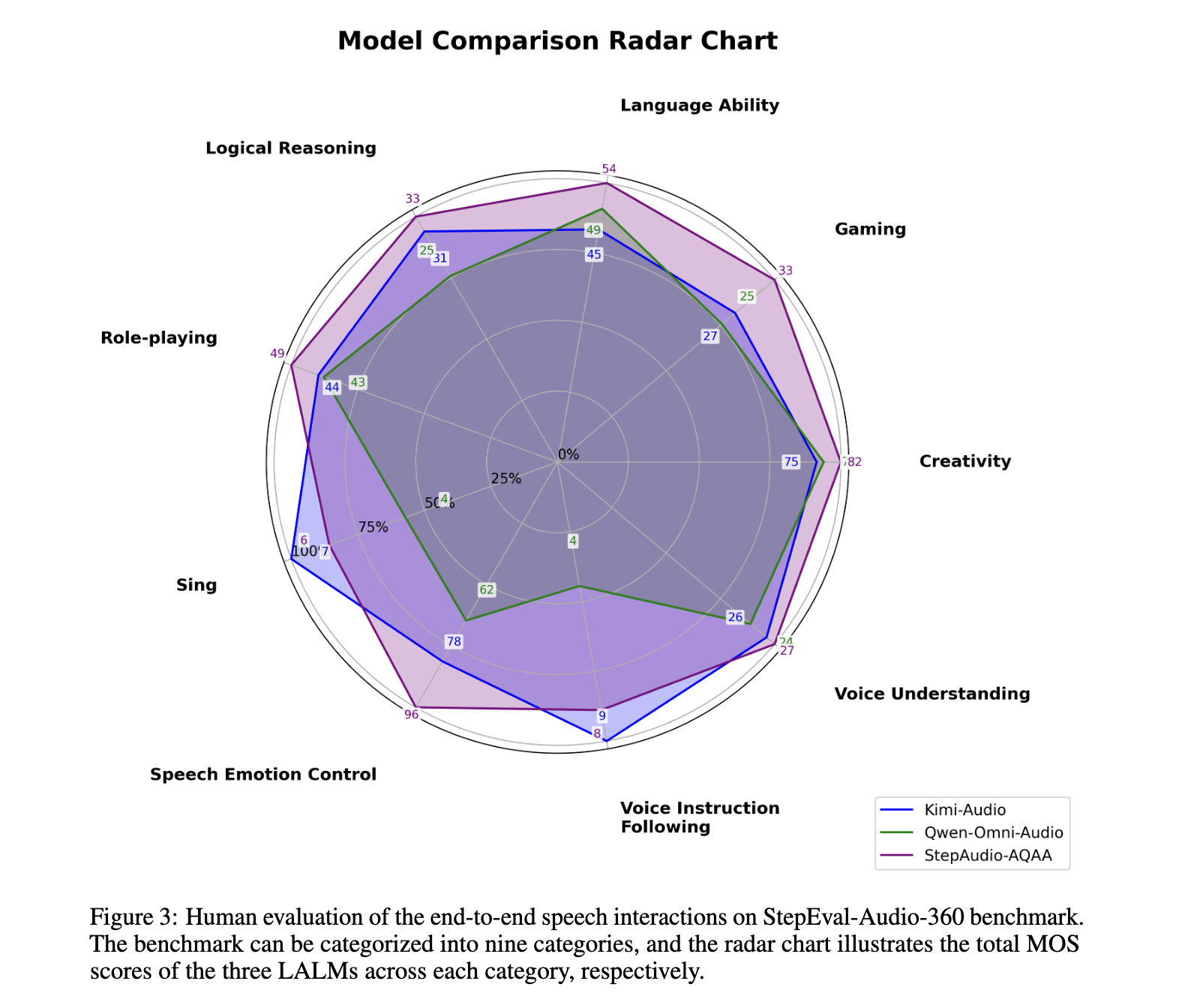
Benchmark evaluation and results
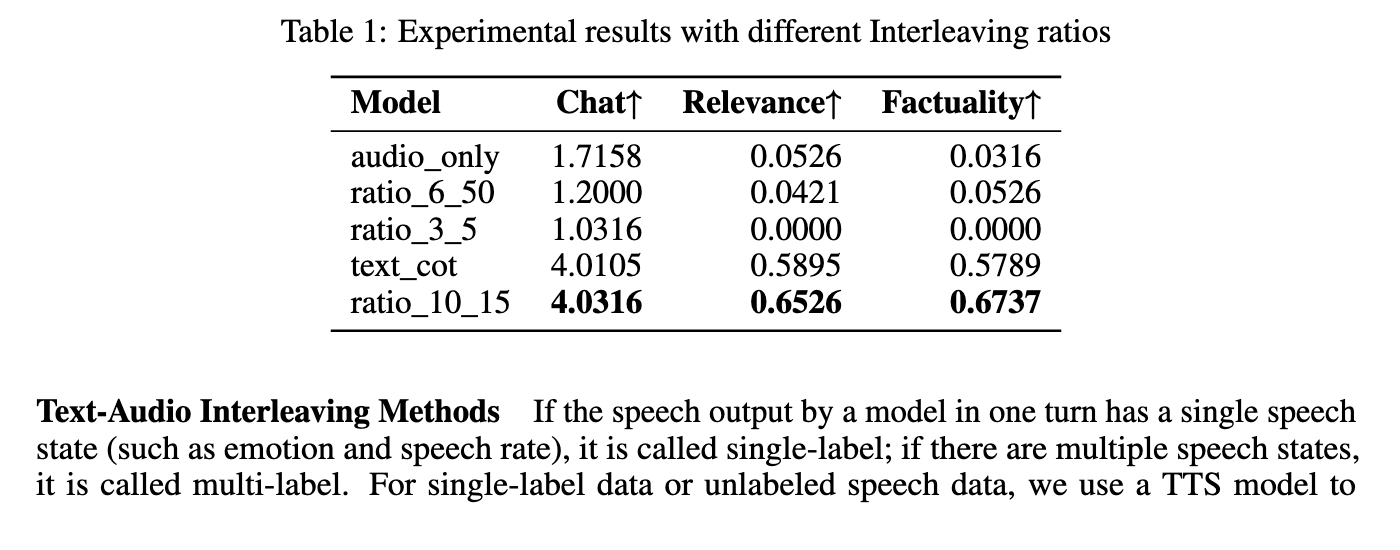
The model was evaluated using the Stepeval-Audio-360 benchmark, which includes multilingual, multilingual rectal audio tasks across nine categories, including creativity, gaming, gaming, emotion control, role-playing, and speech comprehension. Compared to the latest models such as Kimi-Audio and Qwen-Omni, Step-Audio-Aqaa has achieved the highest opinion score in most categories. Specifically, in the text principle token ratio experiment, the configuration with a 10:15 ratio scored with CHAT (4.03), correlation (0.65) and fact (0.67) scores achieved the best performance. Among different audio interleaving techniques, the tandem performance of the retained markers is best, with chat (4.22), correlation (0.57) and fact (0.57) score (0.57). These numbers reflect their power in producing semantic accuracy, emotional affluence, and background-perceived audio response.
Conclusion: Towards a expressive speech
Step-Audio-AQAA provides a powerful solution to the limitations of modular voice processing pipelines. By combining expressive audio tokenization, powerful multi-modal LLM and advanced post-training training strategies such as direct preference optimization and model merging, it successfully produces high-quality, emotionally resonant audio responses. This work marks an important step in enabling machines to communicate with voice not only functional, but also expressive and fluid.
Check Paper and model hugging face. All credits for this study are to the researchers on the project. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Nikhil is an intern consultant at Marktechpost. He is studying for a comprehensive material degree in integrated materials at the Haragpur Indian Technical College. Nikhil is an AI/ML enthusiast and has been studying applications in fields such as biomaterials and biomedical sciences. He has a strong background in materials science, and he is exploring new advancements and creating opportunities for contribution.





