log links vs. log conversion in R – misleading the difference in your entire data analysis

Distribution is most commonly used, and unfortunately, many real-world data are abnormal. When faced with extremely skewed data, it is easy to use log transformations to normalize the distribution and stabilize the variance. I recently conducted a project using data from Epoch AI to analyze the energy consumption of training AI models [1]. There is no official data on energy usage for each model, so I calculated it by multiplying the power pull time for each model by training time. The new variables (in kWh) are highly right-handed, as well as some extreme and over-dispersed outliers (Figure 1).
To address this skewness and heterosexuality, my first instinct was to apply log transformations to energy variables. The distribution of logs (energy) looks more normal (Figure 2), while the shapiro-Wilk test confirms boundary normality (p≈0.5).

Modeling puzzles: log conversion and log linking
The visualization looks good, but as I continue to model, I face the dilemma: it should be modeled Logarithmic conversion response variable ((log(Y) ~ X),,,,, Or should I model Original response variable use Log link function ((Y ~ X, link = “log")? I also considered two distributions: Gaussian (normal) and gamma distribution – and combined each distribution with two log methods. This gives me four different models as shown below, all of which are fitted using a generalized linear model (GLM) of R:
all_gaussian_log_link Model comparison: AIC and diagnostic chart
I compared these four models using the Akaike Information Standard (AIC), which is an estimator for prediction errors. Generally, the lower the AIC, the better the model fit.
AIC(all_gaussian_log_link, all_gaussian_log_transform, all_gamma_log_link, all_gamma_log_transform)
df AIC
all_gaussian_log_link 25 2005.8263
all_gaussian_log_transform 25 311.5963
all_gamma_log_link 25 1780.8524
all_gamma_log_transform 25 352.5450Among these four models, the AIC value of the model using log-transformed results is much lower than that using log-linked models. Since the AICs vary widely between log-transformation and log-linked models (311 and 352 vs 1780 and 2005), I also checked the diagnostic plot to further verify that this log-transformation model has a better fit:




Based on the AIC values and diagnostic graphs, I decided to move forward with the gamma model of logarithmic transformation, because it has the second lowest AIC value, and its residuals and fit graphs look better than the logarithmic transformation Gaussian model.
I continue to explore which explanatory variables are useful and which interactions may be important. The final model I chose was:
glm(formula = log(Energy_kWh) ~ Training_time_hour * Hardware_quantity +
Training_hardware + 0, family = Gamma(), data = df)Explanation coefficient
However, when I started explaining the coefficients of the model, there were some things that were upset. Since only the response variable is logarithmic, the effect of the predictor variable is multiplicative, and we need to point out the coefficients to convert them back to the original scale. Single unit increase of 𝓍 Multiply the result by exp(β), or each additional unit in 𝓍 causes (exp(β) – 1) × 100% change. [2].
Check out the result table of the model below, we have Triending_time_hour, hardware_quantity, Interacting terms with them triending_time_hour:hardware_quantity are continuous variables, so their coefficients represent slope. Meanwhile, since I specify +0 in the model formula, all levels of the classification are Triending_hardware acts as an intercept, which means that each hardware type acts as an intercept β₀ when the corresponding dummy variable is active.
> glm(formula = log(Energy_kWh) ~ Training_time_hour * Hardware_quantity +
Training_hardware + 0, family = Gamma(), data = df)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
Training_time_hour -1.587e-05 3.112e-06 -5.098 5.76e-06 ***
Hardware_quantity -5.121e-06 1.564e-06 -3.275 0.00196 **
Training_hardwareGoogle TPU v2 1.396e-01 2.297e-02 6.079 1.90e-07 ***
Training_hardwareGoogle TPU v3 1.106e-01 7.048e-03 15.696 When converting the slope to a percentage change in response to variables, the effect of each continuous variable is almost zero, even slightly negative: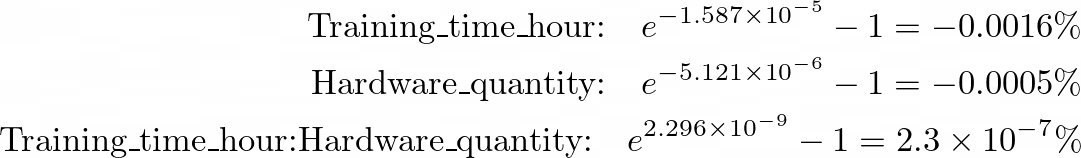
All intercepts are also converted back to the original scale only about 1 kWh. The result makes no sense, because at least one of the slopes increases with huge energy consumption. I’m wondering if using a logarithmic chaining model with the same predictor variables could produce different results, so I’m fitting the model again:
glm(formula = Energy_kWh ~ Training_time_hour * Hardware_quantity +
Training_hardware + 0, family = Gamma(link = "log"), data = df)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
Training_time_hour 1.818e-03 1.640e-04 11.088 7.74e-15 ***
Hardware_quantity 7.373e-04 1.008e-04 7.315 2.42e-09 ***
Training_hardwareGoogle TPU v2 7.136e+00 7.379e-01 9.670 7.51e-13 ***
Training_hardwareGoogle TPU v3 1.004e+01 3.156e-01 31.808 this time, Training_Time and Hardware_Quantity Total energy consumption per hour will increase by 0.18% and 0.07% per chip. At the same time, their interaction will reduce energy use by 2×10⁵%. These results are more meaningful because Training_Time It can reach 7000 hours, and Hardware_Quantity Up to 16,000 units.

To better visualize the differences, I created two graphs comparing the predictions of the two models (shown as dotted lines). The left panel uses a logarithmic transformation of gamma GLM model in which the dotted line is almost flat and close to zero, far from the solid line of the fitted original data. On the other hand, the right panel uses a logarithmic link gamma GLM model, where the dotted lines are more closely aligned with the actual fitted lines.
test_data %
mutate(
pred_energy1 = exp(predict(glm3, newdata = test_data)),
pred_energy2 = predict(glm3_alt, newdata = test_data, type = "response"),
)
y_limits 
Why log conversion failed
To understand why the fundamental effects cannot be captured as links for the log transformation model, let’s browse what happens when we apply log transformations to response variables:
Assume that y is equal to x and some functions plus the error term:

When we apply the log transformation to y, we are actually compressing F(x) and error:

This means we are modeling a completely new response variable, log(y). When we insert our own function g(x) – in my case g(x) = trialing_time_hour*hardware_quantity + Training_hardware– It tries to capture the combined effect of “shrink” F(x) and error terms.
Instead, when we use log links, we are still modeling the original Y, not the converted version. Instead, the model instructs our own function g(x) to predict y.

The model then minimizes the difference between the actual Y and the predicted Y. This way, the error term remains intact on the original scale:

in conclusion
Log transformation variables are different from using log links and may not always produce reliable results. Under the hood, the logarithmic transformation changes the variable itself and distorts the change and noise. Understanding this subtle mathematical difference behind a model is as important as trying to find the most suitable model.
[1] Epoch ai. Data about famous AI models . from
[2] University of Virginia Library. Interpret log transformations in a linear model.from



