
study
Supervised learning is a category of machine learning that uses marked data sets to train algorithms to predict results and identify patterns.
Unlike unsupervised learning, supervised learning algorithms are marked as training to learn the relationship between input and output.
Prerequisite: Linear Algebra
Suppose we have one Regression question The model needs to predict where continuous values are predicted by ingesting n input functions (XI).
The predicted value is defined as a function Assumptions (h):
Where:
- θi: i-th parameter corresponds to each input function (x_i),
- ϵ(epsilon): Gaussian error (ϵ ~ n (0, σ²)))
Since the assumption of a single input produces a scalar value (Hθ(x)∈R), it can be expressed as Transpose of parameter vectors (θt) and The eigenvector of this input (x):

Batch gradient descent
Gradient descent It is an iterative optimization algorithm used to find the local minimum value of the function. In each step, it moves in the opposite direction of the steepest descending direction to gradually lower the value of the function – simply continue downhill.
Now, recall that we have n parameters that affect the prediction. Therefore, we need to know Single parameter (θi) corresponds to training data (XI)) to function.
Suppose we set the size of each step to the learning rate (α) and find a cost curve (J) and then deduct the parameter in each step so that:

((α: Learning rate, j(θ): cOST function, ∂/∂θi: Partial derivative relative to the cost function θi)
slope
The gradient represents the slope of the cost function.
Taking into account the residual parameters of the cost function and its corresponding partial derivative (J), the gradient of the cost function of the n parameter is defined as:

Gradients are matrix representations of partial derivatives of cost functions relative to all parameters (θ0 to θn).
Since the learning rate is a scalar (α∈R), the update rules of the gradient descent algorithm are expressed in matrix notation:

at last, The parameter (θ) is located in the (n+1) dimension space.
Geographically, it goes downhill with steps corresponding to the learning rate until convergence is reached.

calculate
The purpose of linear regression is to minimize the gap (MSE) between predicted and actual values in the training dataset.
Cost function (target function)
This gap (MSE) is defined as the average gap for all training examples:

Where
- jθ: Cost function (or loss function),
- hθ: predict from the model,
- X: I_TH input function,
- Y: I_TH target value, and
- M: Number of training examples.
this slope Calculate by taking The partial derivative of the cost function relative to each parameter:

Because we have n+1 parameters (Including the intercept term θ0) and the M training example, we will use matrix symbols to form a gradient vector:

In matrix symbols, where x represents the design matrix including the intercept term, θ is the parameter vector, and the gradient ∇θJ (θ) is by:

this LMS (minimum square) rules is an iterative algorithm that continuously adjusts the parameters of the model based on the error between its prediction and the actual target values of the training example.
Minimum Square (LMS) Rules
Each era When gradient descent, each parameter θi is updated by subtracting a portion of the mean error in all training examples:

This process allows the algorithm to find iteratively Best parameters Minimize cost features.
(Note: θi is the parameter associated with the input feature XI, and the goal of the algorithm is to find its optimal value, not that it is already an optimal parameter.
Normal equation
turn up Best parameters (θ*) To minimize cost functionality, we can use Normal equation.
This method provides an analytical solution for linear regression, allowing us to directly calculate the θ value of the minimizing cost function.
Unlike iterative optimization techniques, normal equations find the best equation by directly solving points with zero gradients, thus ensuring immediate convergence:

therefore:

It depends on the assumptions of the design matrix x is reversiblewhich means that all its input functions (from x_0 to x_n) are Linear independence.
If x is irreversible, we need to adjust the input features to ensure they are independent of each other.
simulation
In fact, we repeat the process by setting it until converges:
- Cost function and its gradient
- Learning rate
- Tolerance (minimum cost threshold to prevent iteration)
- Maximum number of iterations
- starting point
Batches by learning
The following coding segment shows the process of gradient descent, and the local minimum value of the quadratic cost function is found through the learning rate (0.1, 0.3, 0.8 and 0.9):
def cost_func(x):
return x**2 - 4 * x + 1
def gradient(x):
return 2*x - 4
def gradient_descent(gradient, start, learn_rate, max_iter, tol):
x = start
steps = [start] # records learning steps
for _ in range(max_iter):
diff = learn_rate * gradient(x)
if np.abs(diff) 
Predicting credit card transactions
Let’s use the sample dataset on Kaggle, using batch GD to predict credit card transactions using linear regression.
1. Data preprocessing
a) Basic data frame
First, we will use the ID as the key to merge these four files in the sample dataset while cleaning up the original data:
- Transaction (CSV)
- User (CSV)
- Credit Card (CSV)
- train_fraud_labels(json)
# load transaction data
trx_df = pd.read_csv(f'{dir}/transactions_data.csv')
# sanitize the dataset
trx_df = trx_df[trx_df['errors'].isna()]
trx_df = trx_df.drop(columns=['merchant_city','merchant_state', 'date', 'mcc', 'errors'], axis='columns')
trx_df['amount'] = trx_df['amount'].apply(sanitize_df)
# merge the dataframe with fraud transaction flag.
with open(f'{dir}/train_fraud_labels.json', 'r') as fp:
fraud_labels_json = json.load(fp=fp)
fraud_labels_dict = fraud_labels_json.get('target', {})
fraud_labels_series = pd.Series(fraud_labels_dict, name='is_fraud')
fraud_labels_series.index = fraud_labels_series.index.astype(int)
merged_df = pd.merge(trx_df, fraud_labels_series, left_on='id', right_index=True, how='left')
merged_df.fillna({'is_fraud': 'No'}, inplace=True)
merged_df['is_fraud'] = merged_df['is_fraud'].map({'Yes': 1, 'No': 0})
merged_df = merged_df.dropna()
# load card data
card_df = pd.read_csv(f'{dir}/cards_data.csv')
card_df = card_df.replace('nan', np.nan).dropna()
card_df = card_df[card_df['card_on_dark_web'] == 'No']
card_df = card_df.drop(columns=['acct_open_date', 'card_number', 'expires', 'cvv', 'card_on_dark_web'], axis='columns')
card_df['credit_limit'] = card_df['credit_limit'].apply(sanitize_df)
# load user data
user_df = pd.read_csv(f'{dir}/users_data.csv')
user_df = user_df.drop(columns=['birth_year', 'birth_month', 'address', 'latitude', 'longitude'], axis='columns')
user_df = user_df.replace('nan', np.nan).dropna()
user_df['per_capita_income'] = user_df['per_capita_income'].apply(sanitize_df)
user_df['yearly_income'] = user_df['yearly_income'].apply(sanitize_df)
user_df['total_debt'] = user_df['total_debt'].apply(sanitize_df)
# merge transaction and card data
merged_df = pd.merge(left=merged_df, right=card_df, left_on='card_id', right_on='id', how='inner')
merged_df = pd.merge(left=merged_df, right=user_df, left_on='client_id_x', right_on='id', how='inner')
merged_df = merged_df.drop(columns=['id_x', 'client_id_x', 'card_id', 'merchant_id', 'id_y', 'client_id_y', 'id'], axis='columns')
merged_df = merged_df.dropna()
# finalize the dataframe
categorical_cols = merged_df.select_dtypes(include=['object']).columns
df = merged_df.copy()
df = pd.get_dummies(df, columns=categorical_cols, dummy_na=False, dtype=float)
df = df.dropna()
print('Base data frame: n', df.head(n=3))
b) Preprocessing
From the basic data frame, we will select the appropriate input function:
Continuous values, and linear relationship with transaction amount.
df = df[df['is_fraud'] == 0]
df = df[['amount', 'per_capita_income', 'yearly_income', 'credit_limit', 'credit_score', 'current_age']]Then we will filter offline beyond 3 standard deviations away from the mean:
def filter_outliers(df, column, std_threshold) -> pd.DataFrame:
mean = df[column].mean()
std = df[column].std()
upper_bound = mean + std_threshold * std
lower_bound = mean - std_threshold * std
filtered_df = df[(df[column] = lower_bound)]
return filtered_df
df = df.replace(to_replace='NaN', value=0)
df = filter_outliers(df=df, column='amount', std_threshold=3)
df = filter_outliers(df=df, column='per_capita_income', std_threshold=3)
df = filter_outliers(df=df, column='credit_limit', std_threshold=3)Finally, we will get the logarithm of the target value amount Reduce skew distribution:
df['amount'] = df['amount'] + 1
df['amount_log'] = np.log(df['amount'])
df = df.drop(columns=['amount'], axis='columns')
df = df.dropna()*Added one quantity To avoid infinite Quantity_log Pillar.
Final data framework:

c) Transformer
Now we can separate the final data frame and convert it into a train/test dataset:
categorical_features = X.select_dtypes(include=['object']).columns.tolist()
categorical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')),('onehot', OneHotEncoder(handle_unknown='ignore'))])
numerical_features = X.select_dtypes(include=['int64', 'float64']).columns.tolist()
numerical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='mean')), ('scaler', StandardScaler())])
preprocessor = ColumnTransformer(
transformers=[
('num', numerical_transformer, numerical_features),
('cat', categorical_transformer, categorical_features)
]
)
X_train_processed = preprocessor.fit_transform(X_train)
X_test_processed = preprocessor.transform(X_test)2. Define a batch GD regressor
class BatchGradientDescentLinearRegressor:
def __init__(self, learning_rate=0.01, n_iterations=1000, l2_penalty=0.01, tol=1e-4, patience=10):
self.learning_rate = learning_rate
self.n_iterations = n_iterations
self.l2_penalty = l2_penalty
self.tol = tol
self.patience = patience
self.weights = None
self.bias = None
self.history = {'loss': [], 'grad_norm': [], 'weight':[], 'bias': [], 'val_loss': []}
self.best_weights = None
self.best_bias = None
self.best_val_loss = float('inf')
self.epochs_no_improve = 0
def _mse_loss(self, y_true, y_pred, weights):
m = len(y_true)
loss = (1 / (2 * m)) * np.sum((y_pred - y_true)**2)
l2_term = (self.l2_penalty / (2 * m)) * np.sum(weights**2)
return loss + l2_term
def fit(self, X_train, y_train, X_val=None, y_val=None):
n_samples, n_features = X_train.shape
self.weights = np.zeros(n_features)
self.bias = 0
for i in range(self.n_iterations):
y_pred = np.dot(X_train, self.weights) + self.bias
dw = (1 / n_samples) * np.dot(X_train.T, (y_pred - y_train)) + (self.l2_penalty / n_samples) * self.weights
db = (1 / n_samples) * np.sum(y_pred - y_train)
loss = self._mse_loss(y_train, y_pred, self.weights)
gradient = np.concatenate([dw, [db]])
grad_norm = np.linalg.norm(gradient)
# update history
self.history['weight'].append(self.weights[0])
self.history['loss'].append(loss)
self.history['grad_norm'].append(grad_norm)
self.history['bias'].append(self.bias)
# descent
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
if X_val is not None and y_val is not None:
val_y_pred = np.dot(X_val, self.weights) + self.bias
val_loss = self._mse_loss(y_val, val_y_pred, self.weights)
self.history['val_loss'].append(val_loss)
if val_loss = self.patience:
print(f"Early stopping at iteration {i+1} (validation loss did not improve for {self.patience} epochs)")
self.weights = self.best_weights
self.bias = self.best_bias
break
if (i + 1) % 100 == 0:
print(f"Iteration {i+1}/{self.n_iterations}, Loss: {loss:.4f}", end="")
if X_val is not None:
print(f", Validation Loss: {val_loss:.4f}")
else:
pass
def predict(self, X_test):
return np.dot(X_test, self.weights) + self.bias3. Forecasting and evaluation
model = BatchGradientDescentLinearRegressor(learning_rate=0.001, n_iterations=10000, l2_penalty=0, tol=1e-5, patience=5)
model.fit(X_train_processed, y_train.values)
y_pred = model.predict(X_test_processed)Output:
Among the five input functions, per_capita_income Shows the highest correlation with transaction volume: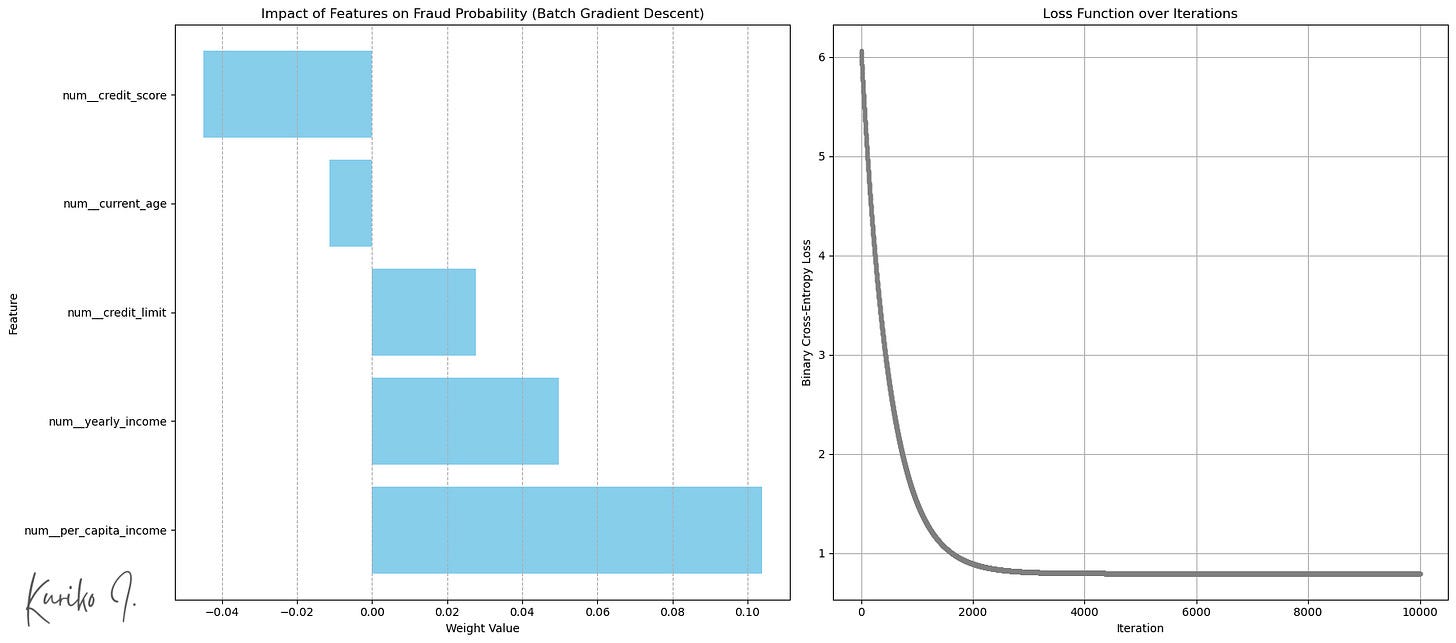
(Left: Input Function (Bottom: More Transactions), Right: Cost Function (Learning_rate = 0.001, i = 10,000, M = 50,000, n = 5))
Square Error (MSE): 1.5752
R square: 0.0206
Average Absolute Error (MAE): 1.0472
Time complexity: Training: O(N²M +N³) + Forecast: O(N)
Space complexity: o(nm)
(M: training example size, n: input feature size, assuming M >>> n)
Stochastic gradient descent
Batch processing GD usage The entire training dataset To calculate the gradients in each iteration step (epoch), this is computationally expensive, especially when we have millions of data sets.
Stochastic Gradient Descent (SGD) on the other hand,
- Usually, training data will be shuffled at the beginning of each period.
- Random selection one Single Training examples In each iteration,
- Use examples to calculate the gradient, and
- Update the weights and deviations of the model After processing each individual training example.
This results in weight updates per epoch (equal to the number of training samples), many fast and computationally cheap updates based on a single data point, Allows it to iterate through large datasets at a speed.
simulation
Similar to batch GD, we will define the SGD class and run the prediction:
class StochasticGradientDescentLinearRegressor:
def __init__(self, learning_rate=0.01, n_iterations=100, l2_penalty=0.01, random_state=None):
self.learning_rate = learning_rate
self.n_iterations = n_iterations
self.l2_penalty = l2_penalty
self.random_state = random_state
self._rng = np.random.default_rng(seed=random_state)
self.weights_history = []
self.bias_history = []
self.loss_history = []
self.weights = None
self.bias = None
def _mse_loss_single(self, y_true, y_pred):
return 0.5 * (y_pred - y_true)**2
def fit(self, X, y):
n_samples, n_features = X.shape
self.weights = self._rng.random(n_features)
self.bias = 0.0
for epoch in range(self.n_iterations):
permutation = self._rng.permutation(n_samples)
X_shuffled = X[permutation]
y_shuffled = y[permutation]
epoch_loss = 0
for i in range(n_samples):
xi = X_shuffled[i]
yi = y_shuffled[i]
y_pred = np.dot(xi, self.weights) + self.bias
dw = xi * (y_pred - yi) + self.l2_penalty * self.weights
db = y_pred - yi
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
epoch_loss += self._mse_loss_single(yi, y_pred)
if n_features >= 2:
self.weights_history.append(self.weights[:2].copy())
elif n_features == 1:
self.weights_history.append(np.array([self.weights[0], 0]))
self.bias_history.append(self.bias)
self.loss_history.append(self._mse_loss_single(yi, y_pred) + (self.l2_penalty / (2 * n_samples)) * (np.sum(self.weights**2) + self.bias**2)) # Approx L2
print(f"Epoch {epoch+1}/{self.n_iterations}, Loss: {epoch_loss/n_samples:.4f}")
def predict(self, X):
return np.dot(X, self.weights) + self.bias
model = StochasticGradientDescentLinearRegressor(learning_rate=0.001, n_iterations=200, random_state=42)
model.fit(X=X_train_processed, y=y_train.values)
y_pred = model.predict(X_test_processed)Output:
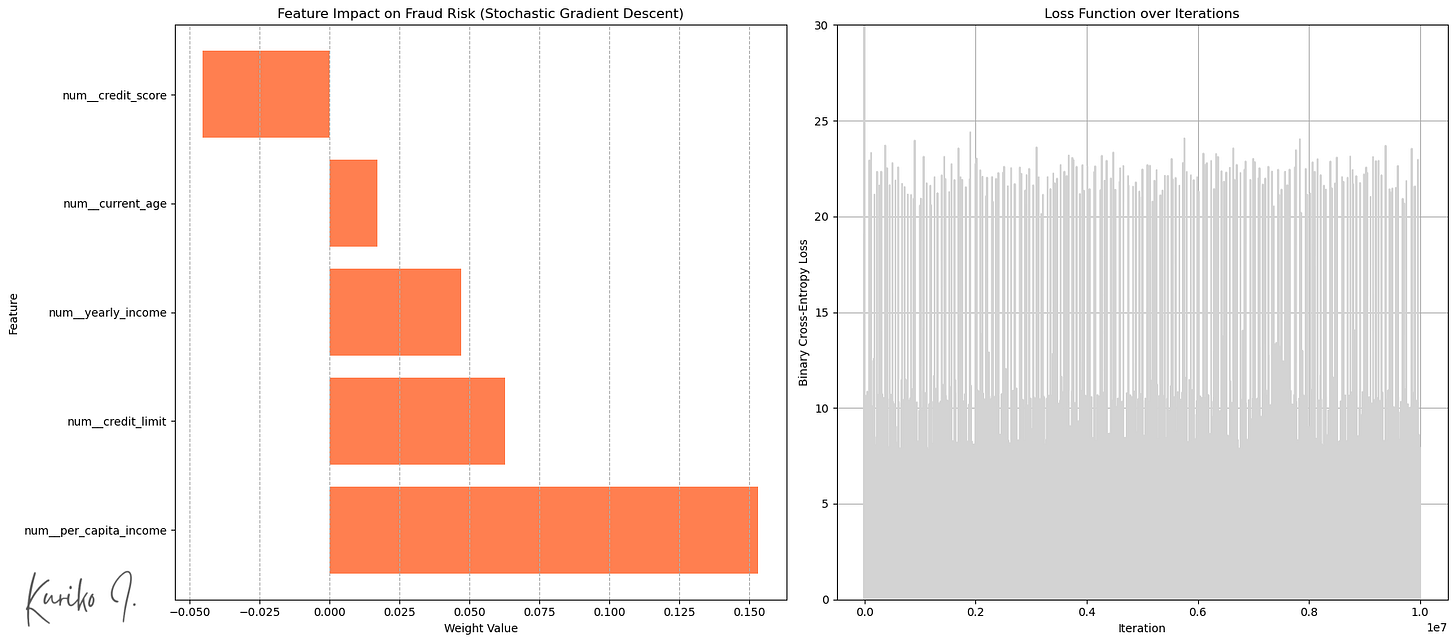
Left: The weight of the input function, right: Cost function (cost function (Learning_rate= 0.001, i = 200, m = 50,000, n = 5)
Introduced SGD Randomity Enter the optimization process (right of the figure).
this “noise” Can help with the algorithm Break out of shallow local minimum or saddle point And it is possible to find a better area of parameter space.
result:
Square Error (MSE): 1.5808
R square: 0.0172
Average Absolute Error (MAE): 1.0475
Time complexity: Training: O(N²M +N³) + Forecast: O(N)
Space complexity: exist)
(M: training example size, n: input feature size, assuming M >>> n)
in conclusion
and Simple linear model Computationally valid, its inherent simplicity often prevents it from capturing complex relationships in the data.
Consider trade off Various modeling methods for specific goals are crucial to achieving the best results.
refer to
Unless otherwise stated, all images are by the author.
This article uses synthetic data and is licensed under Apache 2.0 for commercial use.
Author: Kuriko Iwai
Portfolio/LinkedIn/github



