How the potential vector field reveals the internal work of neural autoencoders

Autoencoder and potential space
Neural networks are designed to learn compressed representations of high-dimensional data, and automatic encoders (AES) are a broad example of such models. These systems use an encoder decoder structure to project data into a low-dimensional latent space and then reconstruct it back to its original form. In this potential space, the patterns and functions of the input data become more interpretable, allowing various downstream tasks to be performed. Because they are able to represent complex distributions through more manageable structured representations, autoencoders have been widely used in areas such as image classification, generative modeling, and anomaly detection.
Generalization in memory and neural models
The ongoing problem with neural models, especially autoencoders, is determining how they strike a balance between memorizing training data and generalizing to invisible examples. This balance is crucial: If the model is overfitted, it may not be possible to perform on new data; if it generalizes too much, it may lose useful details. Researchers are particularly interested in whether these models encode knowledge in ways that can be revealed and measured, even without direct input of data. Understanding this balance can help optimize model design and training strategies to gain insight into what neural models retain from the data they process.
Existing detection methods and their limitations
Current techniques that detect this behavior usually analyze performance metrics, such as reconstruction errors, but these errors only scratch the surface. Other methods use modifications to models or inputs to gain insight into internal mechanisms. However, they usually do not disclose how model structure and training dynamics affect learning outcomes. The need for deeper representation promotes the study of more inherent and explainable approaches beyond traditional indicators or building adjustments.
Perspective of potential vector fields: dynamic systems in latent space
Researchers from the University of IST Austria and Sapienza have proposed a new approach to interpreting an automated encoder as a dynamic system that runs in a potential space. By repeatedly applying the encoding decoding functions on the latent points, they construct a potential vector field that reveals attractive attractors – the data represents the stable point in the latent space of settlement. This field is inherently present in any autoencoder and does not require changes to the model or other training. Their approach helps visualize how data moves through models and how these movements relate to generalization and memory. They tested this in the dataset and even the underlying model, extending its insights beyond the synthetic benchmark.
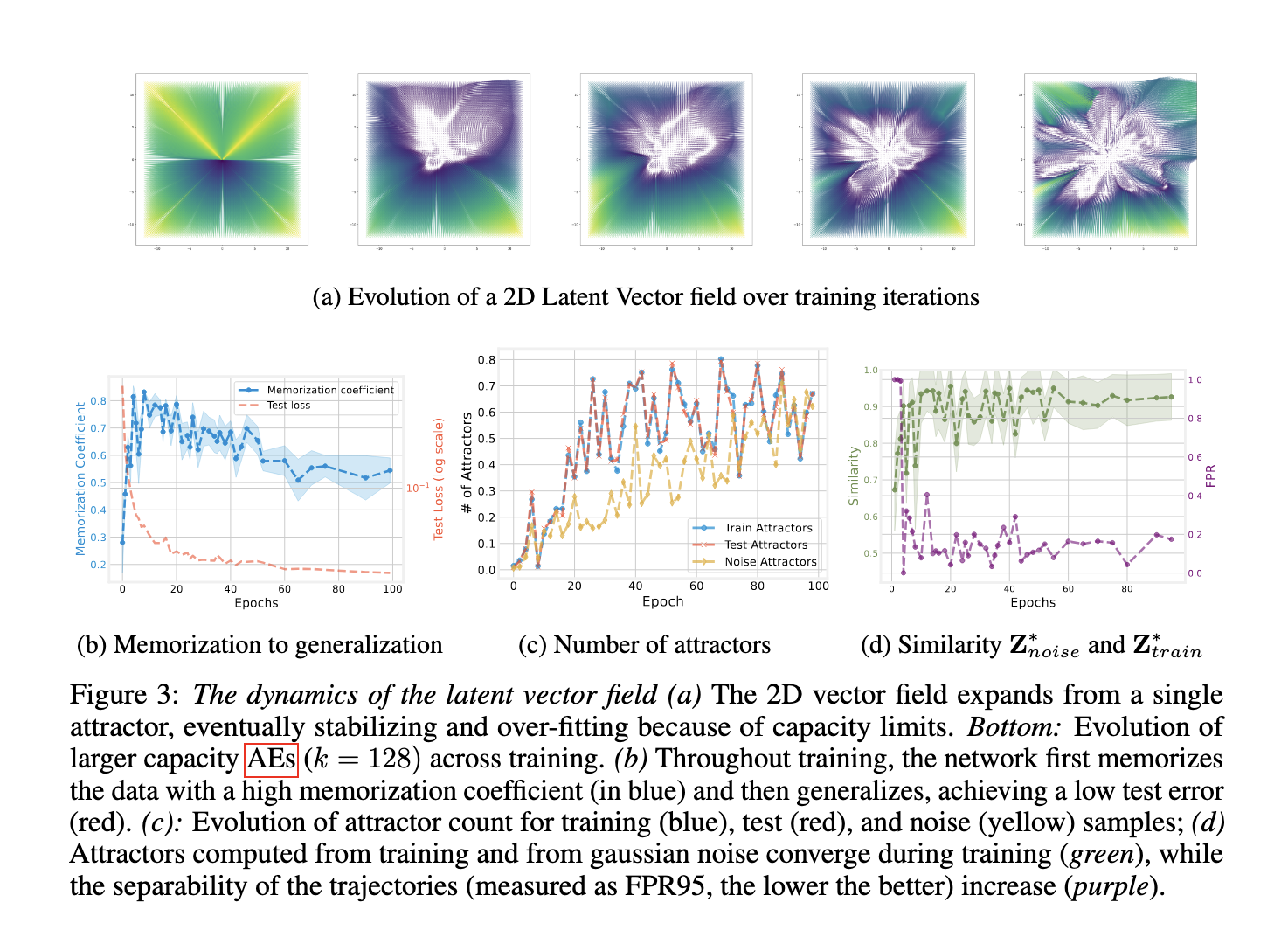
The role of iterative mapping and shrinkage
This method involves applying the repetition of the encoder mapping as discrete differential equations. In this formula, any points in the latent space are iteratively mapped, forming a trajectory defined by the residual vector between each iteration and its input. If the mapping is of some degree, i.e. each application shrinks the space, the system will stabilize on a fixed point or attractor. Researchers show that common design choices, such as weight loss, small bottleneck dimensions, and enhancement-based training, naturally promote this contraction. Thus, the latent vector fields act as an implicit summary of training dynamics, revealing how and where the model encodes the data.
Experience results: Attractor coding model behavior
Performance tests show that these attractors encode key features of the model’s behavior. When training convolution AEs of MNIST, CIFAR10 and FashionMnist, it was found that lower bottleneck dimensions (2 to 16) resulted in high memory coefficients above 0.8, while higher dimensions supported generalization by reducing test errors. The number of attractors increases with the number of training periods, starting from one, and stabilizing as training progresses. In detecting visual fundamental models predicted on LAION2B, the researchers reconstructed data from six different datasets using attractors derived purely from Gaussian noise. With a sparsity of 5%, reconstruction is significantly better than reconstruction of random orthogonal basis. The mean squared error is always low, indicating that the attractor forms a compact and effective dictionary of representation.
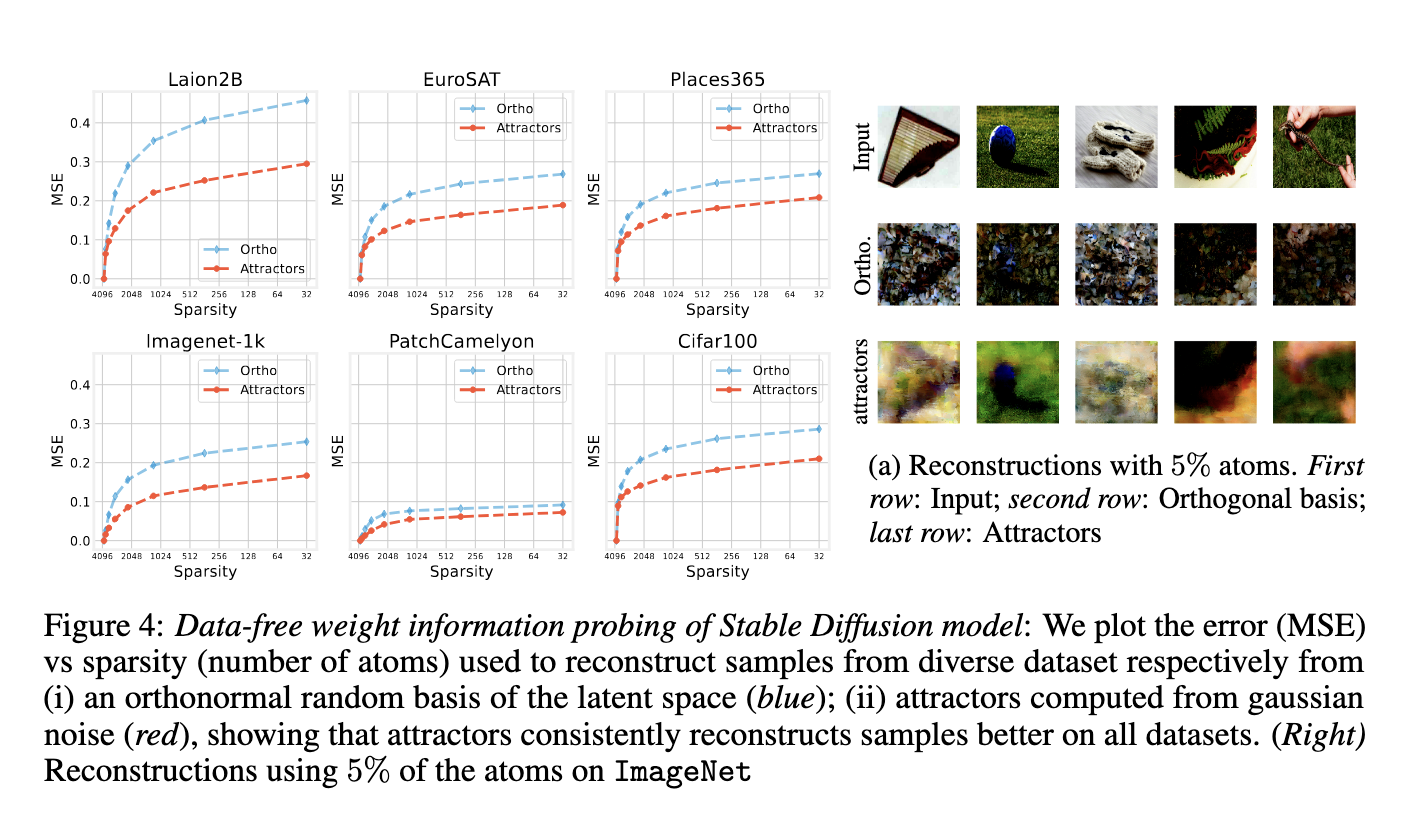
Significance: Advancing the explanatory nature of the model
This work highlights a novel and powerful approach to examining how the Vernacular model stores and uses information. Researchers from IST Austria and Sapienza revealed that attractors in potential vector fields provide a clear window for the ability to generalize or remember models. Their findings suggest that even without input data, latent dynamics can reveal the structure and limitations of complex models. The tool can greatly help develop more interpretable AI systems by revealing what these models learn and how they perform during and after training.
Check Paper. All credits for this study are to the researchers on the project. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Nikhil is an intern consultant at Marktechpost. He is studying for a comprehensive material degree in integrated materials at the Haragpur Indian Technical College. Nikhil is an AI/ML enthusiast and has been studying applications in fields such as biomaterials and biomedical sciences. He has a strong background in materials science, and he is exploring new advancements and creating opportunities for contribution.



 protocol")
