No data sampling is now scalable: Meta-AI releases reward-driven accompanying sampling of generative modeling

Data scarcity in generative modeling
Traditionally, generative models rely on large, high-quality data sets to generate samples that replicate the underlying data distribution. However, in fields such as molecular modeling or physics-based reasoning, obtaining such data may be computationally infeasible, or even impossible. Instead of labeled data, only scalar rewards (usually derived from complex energy functions) can determine the quality of the resulting sample. This presents a significant challenge: How can a person effectively train a generative model without direct supervision of data?
Meta AI introduces accompaniment sampling, a new learning algorithm based on scalar rewards
meta ai solves this challenge Accompaniment samplingThis is a new learning algorithm designed for training generation models using only scalar reward signals. Based on the theoretical framework of random optimal control (SOC), accompaniment sampling rescales the training process into an optimization task during controlled diffusion. Unlike standard generative models, it does not require explicit data. Instead, it generates high-quality samples by iteratively refining using reward functions, usually derived from physical or chemical energy models.
In the case where only improper energy functions can be accessed, the accompanying sampling effect is very high. The samples it produces are consistent with the target distribution defined by that energy, bypassing the need for correction methods such as importance sampling or MCMC, which are computationally intensive.
Technical details
The basis of accompanying sampling is a random differential equation (SDE), which simulates the development of sample trajectory. The algorithm learns a control drift u(x,t)u(x,t)u(x,t), so the final state of these trajectories is approximate to the desired distribution (e.g., boltzmann). The key innovation is its use Mutual Companion Match (RAM)– Enable gradient-based update loss function using only the initial and final states of the sample trajectory. This avoids the need to flow backwards throughout the diffusion path, thereby greatly improving computational efficiency.
The replay buffer of samples and gradients is constructed with sampling by adjusting from known basic processes and terminal state adjustments, allowing multiple optimization steps per sample. This up-policy training method provides unparalleled scalability of previous methods, making it suitable for high-dimensional problems such as the generation of molecular conformational isomers.
In addition, accompanying sampling supports geometric symmetry and periodic boundary conditions, allowing the model to respect molecules such as rotation, translation, and torsion. These characteristics are crucial for physically meaningful generation tasks in chemistry and physics.
Performance insights and benchmark results
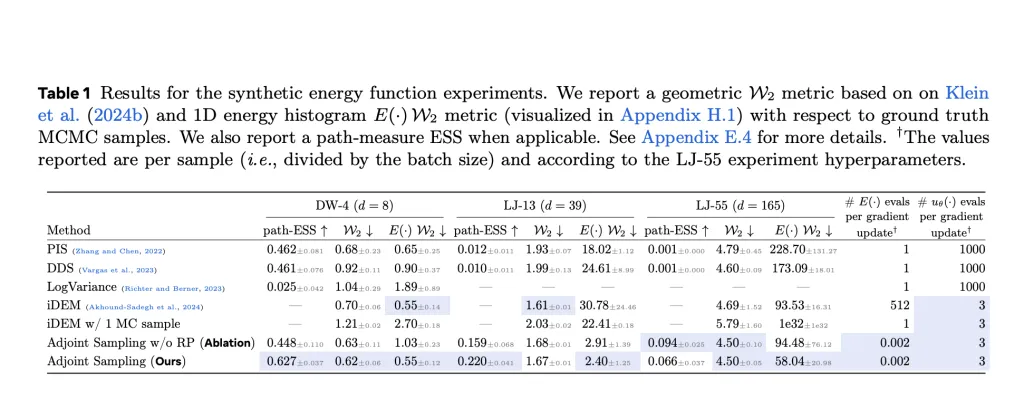
Accompaniment sampling enables the latest comprehensive and realistic tasks. It significantly outperforms baselines such as DDS and PI, especially energy efficiency, on synthetic benchmarks such as double-hole (DW-4), Lennard-Jones (LJ-13 and LJ-55) potentials. For example, if DDS and PI require 1000 evaluations per gradient update, only three are used with accompanying sampling, with similar or better performance in Wasserstein distance and effective sample size (ESS).
In a practical environment, an algorithm for generating evaluation of large-scale molecular conformers using ESEN energy models trained in the Spice-Matz-critical dataset. Accompanied sampling, especially its pretreatment Cartesian variant, reached 96.4% recall and 0.60Å average RMSD, surpassing the RDKIT ETKDG, a widely used chemistry-based baseline – all metrics can reach all metrics. This method can be well summarized to the Geom-Drugs dataset, showing substantial improvements in recall while maintaining competition accuracy.
The algorithm is able to explore the ability to configure space extensively in its random initialization and reward-based learning, thereby improving greater simultaneous diversity, which is crucial for drug discovery and molecular design.
Conclusion: Extensible paths to reward-driven generative models
Accompaniment sampling represents a major step in generative modeling without data. By leveraging scalar reward signals and an effective up-policy training method based on random control, it allows scalable training of diffusion-based samplers with minimal energy assessment. It integrates geometric symmetry and its ability to summarize it in various molecular structures, positioning it as a fundamental tool in computational chemistry and other regions.
View paper, model on hug surface and github page. All credits for this study are to the researchers on the project. Also, please feel free to follow us twitter And don’t forget to join us 95k+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
🚨Build a Genai you can trust. ⭐️Parlant is your open source engine for controlled, compliance and purposeful AI conversations – Star Parlant on Github! (Promotion)



