
OpenBMB releases MiniCPM4: Ultra-efficient language model for edge devices, with little attention and quick reasoning

An effective on-site language model is required
Large language models have become an integral part of AI systems, thus enabling tasks such as multilingual translation, virtual assistance, and automatic reasoning through transformer-based architectures. These models are usually large, but often require a strong cloud infrastructure for training and reasoning. This dependency can lead to incubation periods, high costs, and privacy issues, limiting its deployment to resource-constrained edge devices. Models like GPT and Llama have billions of parameters that cannot be run effectively on local hardware due to their size and the complexity of the training and inference process. Furthermore, their reliance on large data sets and high-performance GPUs makes them unsuitable for mobile or embedded environments. To overcome these challenges, the need for lightweight, effective models can be increasingly performed locally without sacrificing reasoning and context processing capabilities.
Limitations of existing solutions
Several solutions to these challenges have been explored. Sparse attention mechanisms such as NSA and MOBA are designed to reduce memory consumption; however, they either lack in decoding efficiency or introduce important building overhead. For data processing, previous methods have relied on large-scale network scratches, resulting in noisy and unstructured corpus. Filtering methods include FastText classifiers and manual curation, which either lack depth or scalability. In terms of training, frameworks such as Steplaw have been used to optimize hyperparameters according to predictable scaling laws. However, they often require a lot of experimentation and GPU cycles, creating barriers to entry. Inference optimizations, such as flash, reduce computational complexity, but still fail to achieve the speed required for real-time applications on edge devices.
Introduction to MiniCPM4: Effective Architecture, Data, and Inference
Introduction to OpenBMB researchers minicpm4a set of efficient large language models designed specifically for device deployment. The development consists of two variants: one with 500 million parameters, another 8 billion. The model is constructed among four core improvements: model architecture, training data, training algorithms, and inference systems. For the construction, the team introduced INFLLM V2a sparse attention mechanism that speeds pre-filling and decoding without sacrificing contextual understanding. In terms of data, Super clean The training tokens used with QWEN3-8B (e.g., Qwen3-8 B. ModelTunnel V2) can be used to generate and filter training datasets, so only 8 trillion training tokens are used. ModelTunnelv2 guides the training process through effective hyperparameter adjustments, while CPM.CU handles inference with platform-based CUDA based on CPM.CU.
Technology innovation of MiniCPM4
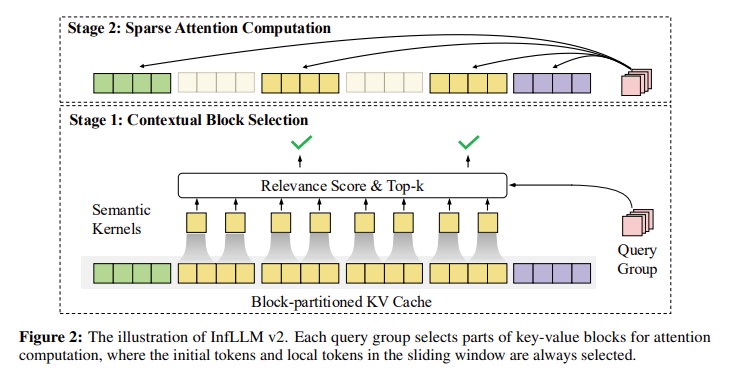
MinicPM4’s Tech stack is designed to balance performance and resource utilization. INPLLM V2 divides the key-value cache into blocks and uses a semantic kernel to select top-k-related blocks for attention, with a 60% reduction in attention calculations compared to NSA. Its dynamic context block selection and token-level query group processing enables it to support sequences of up to 128K tokens while maintaining speed and consistency. Ultraclean leverages pre-trained LLM and annealing-based fine-tuning based on 10 billion tokens to rely on valid data verification. This results in higher quality datasets, UltrafineWeb in English and Ultrafineweb-ZH in Chinese, which outperform 3.61 and 1.98 percentage points in the performance of the average benchmark. Ultrachat V2 further supports training by generating multi-circle conversations rich in reasoning.
Improved benchmark performance and speed
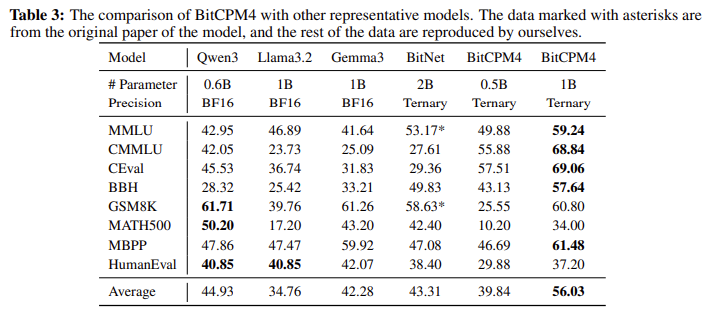
In terms of raw performance, the 8B version had a MMLU score of 32.24%, outperforming FineWeb (28.84%) and FineWeb-Edu (31.80%). On ARC-C and ARC-E, it scored 35.67% and 70.62%, respectively, with more than 10 percentage points and more than 10 percentage points. Compared to QWEN3-8B, MinICPM4 uses only 22% of the training data, but the reasoning speed on 128k length documents is 7 times faster when tested on the peer-side GPU, such as the Jetson AGX Orin and the RTX 4090. Average decoding speeds in 200 tokens (for long-term sexext Exts and shotetects the shortertucty degrades bounds togrances forgranded links shorted links and shorted links degrade corners corners are achieved. In addition, quantization-aware training is enabled using BITCPM4, so that it is deployed on devices with stricter memory constraints without losing performance fidelity.
Key Points of MinicPM4:
- MinicPM4 is 0.5B and 8B parameter sizes, optimized for edge devices.
- It only utilized 8 trillion training tokens, while Qwen3-8 B. 36 trillion.
- Compared to Qwen3-8 B, it achieves 7 times processing of 128 k long documents.
- INFLLM V2 uses block-level attention to reduce the cost of attention calculations by 60%.
- UltrafineWeb outperforms FineWeb on the benchmark at 3.61% (English) and 1.98% (Chinese).
- 35.67% of ARC-C, 70.62% of ARC-E, and MMLU reached 32.24%, surpassing the previous dataset.
- BITCPM4 enables ternary LLM for extremely constrained hardware.
- The CPM.CU reasoning system combines CUDA optimization with speculative sampling.
- Ultrachat V2 enables enhanced fine tuning through inference-intensive dialogue generation.
- ModelTunnel V2 uses a zoom board for precise high-parameter adjustments, which improves training efficiency.
Conclusion: Effective LLM for edge AI applications
In summary, the comprehensive approach adopted by the MinicPM4 team addresses all the critical inefficiencies associated with current LLM. By introducing novel architectural, training and deployment strategies, the model maintains high-quality response, supports novel comprehension and performs well under edge constraints. The success of this work goes beyond the original metrics to demonstrate that state-of-the-art performance can be achieved outside the cloud. It can implement new application domains such as secure offline assistants, real-time mobile AI and automatic embedded systems without the burden of traditional computing.
Check Paper, hug face model and github page. All credits for this study are to the researchers on the project. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.





