
Xiaomi introduces MIMO-7B: a compact language model that surpasses the larger models in math and code reasoning through rigorous pre-training and reinforcement learning

As demand for AI systems continues to increase, tasks involving multi-step logic, mathematical proofs, and software development can be handled, researchers turn their attention to augmenting the inference potential of models. This capability, once considered the uniqueness of human intelligence, is now actively pursued in smaller-scale models to make it more efficient and deployable. As reasoning-based tasks continue to expand relevance, including academic problem solving, automation theorems, algorithm design, and complex software debugging, it is expected that language models will not only become general conversation agents. They are encouraged to become problem solvers in specific areas and they can assist professionals and researchers.
One challenge in building a reasoning-centric model is to achieve powerful simultaneous performance in mathematics and programming while maintaining relatively small model sizes. The most competitive results in these domains are achieved through a model of approximately 32 billion or more parameters. These large models are often used because smaller models strive for generalization and reward optimization in enhanced learning tasks, especially in code-based problem solving. Sparse reward feedback, limited high-quality data and weak underlying model architecture make it difficult to develop compact and powerful models. Furthermore, the data used to train these models does not always take into account inference, often leading to inefficient training and limited growth in problem-solving capabilities.
To address the inference challenge, several models have been introduced, including OpenAI’s O-Series R1 and Claude 3.7, leveraging a large number of parameter counts and complex reinforcement learning strategies. These models use techniques such as step-by-step planning and backtracking to enhance reasoning, especially in algorithmic thinking and math-related tasks. However, they depend heavily on the post-training phase and underestimate the importance of high-quality training data. Many also rely on fixed template-based reward systems that are prone to reward hackers. The benchmarks of code generation often indicate that these models perform inconsistently in challenging tasks due to ineffective reward signal modeling during preprocessing basis and fine-tuning.
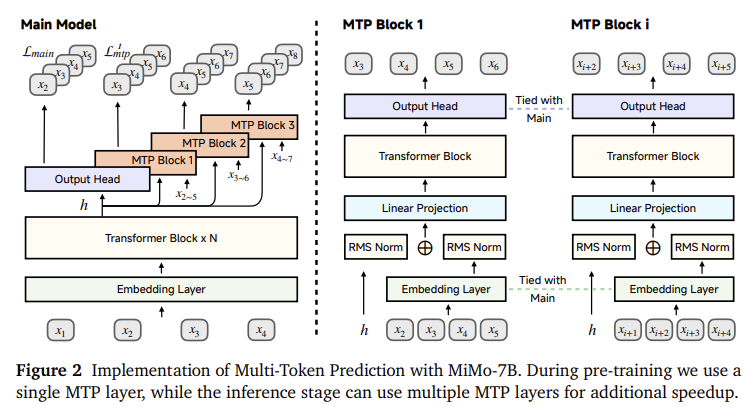
Xiaomi’s research team introduced MIMO-7B Language model families have focused methods to overcome these obstacles. Innovation lies in viewing pre-training and post-training as the same critical stages in developing reasoning abilities. The basic model MIMO-7B basics, using a dataset containing 250,000 tokens to train from scratch. The dataset was constructed with a three-stage mixture strategy that gradually increased the share of mathematical and programming content. Another multi-word prediction (MTP) target was introduced during pre-training to improve performance and inference speed. After training, the team developed a curated dataset of 130,000 verifiable mathematical and programming problems, each marked with difficulty scores. Reinforcement learning is then applied using a hard-driven reward framework, which is more subtle and effective in the training process. This leads to two main variants: MIMO-7B-RL and MIMO-7B-RL-Zero.
The pre-training method begins with extracting weight content from web pages, academic papers, and books using a custom HTML extraction tool, aiming to preserve mathematical equations and code snippets. Unlike general pipelines, this extractor retains structural elements that are critical to solving problem domains. The team then enhanced the PDF parsing tool to accurately interpret scientific and programming content. To prevent data duplication, global deduplication is applied using URL-based Minhash technology. Filter the training corpus using a finely tuned small language model to mark content quality in place of outdated heuristic-based filters that often remove valuable inference examples. High-quality synthetic inference data also comes from advanced models and is added in the final stage of training. This three-stage approach leads to the final training combination, which includes the mathematical and code data for the second stage, and an additional 10% of the synthetic content in the third stage. The maximum context length extends from 8,192 to 32,768 tokens to ensure that the model can solve long-term reasoning problems.
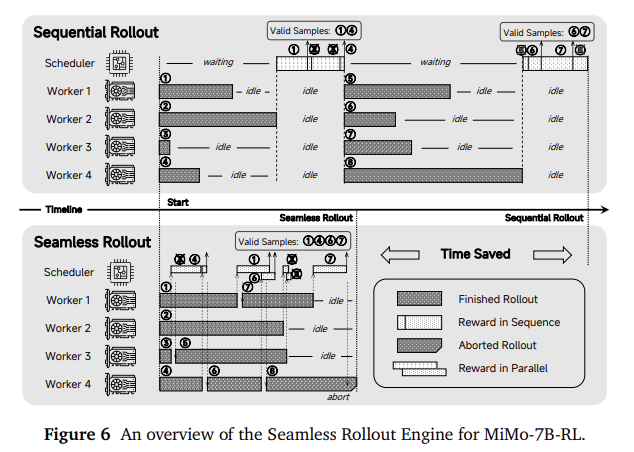
During the reinforcement learning phase, the research team designed a seamless rollout engine to accelerate training and validation. The infrastructure incorporates asynchronous reward calculations and early termination mechanisms to reduce GPU idle time, resulting in 2.29 times faster training and 1.96 times faster verification. The strategy of this model is optimized using fine-grained rewards obtained from the difficulty of the test cases, solving the sparse reward problem in the programming benchmark. Data resampling technology was introduced to maintain training stability and improve rollout sampling efficiency. Together, these strategies enable the MIMO-7B variant to be learned efficiently, even from cold-start states without pre-adjustment.
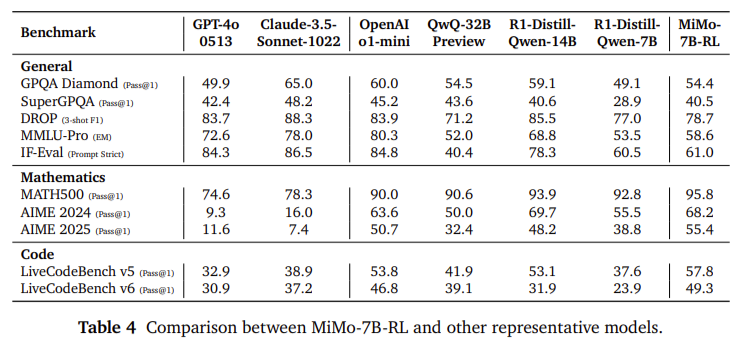
Performance evaluation shows that the MIMO-7B foundation scored 75.2 on the Big Taiwan (BBH) task, surpassing other open source 7B models. It also performs well on SuperGPQA, which includes graduate-level reasoning problems. The training MIMO-7B-RL scored 55.4 on the AIME 2025 benchmark, surpassing Openai’s O1-Mini 4.7 points. On code generation tasks, it outperforms larger models such as livecodebench v5 and v6, such as DeepSeek-R1-Zero-32B and QWEN2.5-32B-RL-Zero. These results show that correctly optimized 7B models can compete or all exceed more than four times the number of parameters.
The MIMO-7B project is a concrete proof that demonstrates how pre-training, data quality and reinforcement learning infrastructure contribute to the ultimate reasoning capabilities of language models. By extracting pipelines from data to reward calculations, Xiaomi research teams have obtained compact and powerful models for real-world applications in mathematics, coding and logic. Their approach highlights the untapped potential of small models and challenges the assumption that only size determines intelligence or versatility.
Key points about MIMO-7B research:
- MIMO-7B is trained on a large data set of 25 trillion tokens to target inference tasks by using a structured data mixture.
- 130,000 math and code problems were used in RL training, and everyone was annotated with difficulty scores to achieve effective reward molding.
- Three-stage pre-training improves mathematical and coding content to 70%, followed by 10% of synthetic problem-solving data.
- The seamless rollout engine has increased RL training speed by 2.29 times and verified speed by 1.96 times.
- MIMO-7B-RL scored 55.4 on AIME 2025, outperforming the Openai O1-Mini with 4.7 points.
- The MIMO-7B model is publicly available and includes all checkpoints: basic, SFT and RL variants.
- The success of this model shows that small, well-designed models can compete with or exceed performance of the 32B model in inference tasks.
Check Paper and github pages. Also, don’t forget to follow us twitter And join us Telegram Channel and LinkedIn GrOUP. Don’t forget to join us 90K+ ml reddit.
🔥 [Register Now] Minicon Agesic AI Virtual Conference: Free Registration + Certificate of Attendance + 4-hour Short Event (May 21, 9am-1pm) + Hands-On the Workshop
Nikhil is an intern consultant at Marktechpost. He is studying for a comprehensive material degree in integrated materials at the Haragpur Indian Technical College. Nikhil is an AI/ML enthusiast and has been studying applications in fields such as biomaterials and biomedical sciences. He has a strong background in materials science, and he is exploring new advancements and creating opportunities for contribution.





